
It cannot have escaped anyone’s attention that at the moment everything is about data, and people often say we need large amounts of data. A slide appears in many presentations with the words: “Data is our new oil!”.
In this blog post, Stefan Palm reflects on the way that data can be converted into information, which then generates knowledge that can be used to generate more knowledge. If you are not following me, keep on reading and you soon will.
Just like with oil, people do not talk very much about how we extract, process and serve these vast amounts of data. But this text is not going to be about Data Engineers, who, like oil drillers, do the heavy labour behind the scenes away from the spotlight.

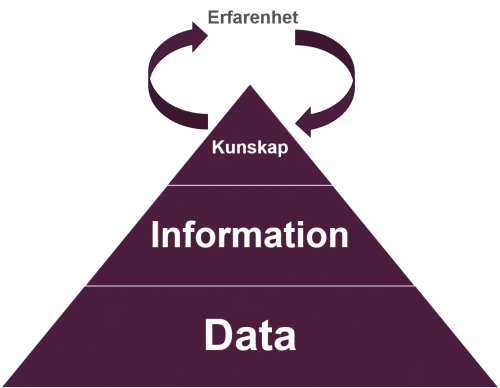
Data in itself is useless
Instead, I would like to highlight the fact that data is fairly useless by itself. Let me try to explain what I mean by giving you an example: 23.
When you have this kind of individual data point, it is virtually impossible to generate anything valuable.
One big challenge is that we do not have any kind of unit linked to our data. Are we talking about 23 dollars, 23 degrees or 23 bananas? This definitely makes a difference. So, let’s add some data: 23 degrees. Has this made it more useful? Well, not that much. Is this the temperature of the bath water? The gradient of a ski slope? Or the temperature in a room? We need to link our data to a context so that we can convert data into information. Information is what gives data a meaning.
So let’s convert our data, with the information that it is 23 degrees in a room. But even now, this information is difficult to interpret. What is the normal temperature in this room? What temperature is it in the room next door? Or outside? It would be good to have this information to compare with. We need to relate our information to something so that we can create insights.
But even if we now have the information that the room is unusually hot (it is normally 21 degrees), probably because the outside temperature is higher than normal, the real value is in being able to link this information to knowledge.
So in our example, the fact that it is 23 degrees is not what we want to know; it is the knowledge of how we reduce the temperature of the room that is most useful for us right now. So in this case, the knowledge that if we put the fan on, the temperature in the room will fall.
But there is actually one thing that can create more knowledge; and this (normally) comes from using knowledge. This is what we call experience. In our case, it means switching the fan on when the outside temperature is increasing, before the room gets too hot.
I hope that we can agree from this example that data in itself is not that useful. But we can convert data to information, and from this information we can generate knowledge. And if we use this knowledge, we gain experience that generates more knowledge. I hope you are following me so far.
How do we make the most of all the knowledge we have in the organisation?
The last piece of the puzzle is that knowledge only generates value when it is used. Although this sounds obvious, in reality it presents a challenge for most organisations. How do we make the most of all the knowledge we have in the organisation? This knowledge is often in the heads of the employees (who have built up knowledge from experience as described above, but I am sure you have understood this).
However, the way we manage knowledge in an organisation is not the focus of this text, although it is something we may come back to. I just want to give you a little food for thought; think about whether the people making the decisions have the most knowledge about what the decisions relate to? Or does the organisation have knowledge that is currently not being used in the decision-making process?
Instead, I want to deviate slightly and look at how technology is used for managing data. It is more the rule than the exception that we also mention Artificial Intelligence (AI) in the same breath. I usually jokingly say that although people say AI, meaning Machine Learning (ML), what actually solves their problems is Analytics. And I have deliberately chosen to write Analytics; BI is too narrow a term for me, but I know people have different opinions on this. (Luckily we live in a country where we are allowed to have different opinions, and understanding why other people think the way they do is an extremely interesting part of the learning process, in my opinion.)
So let’s try to analyse the terms above, and relate them to our thoughts about data, information and knowledge.
Analytics is the ability to gain insights from data. In its broadest sense, this ability is realised using Excel. And Excel remains a fantastic tool, with many organisations continuing to use Excel in their day-to-day operations. However, as the amount of data increases, so does the number of new tools/platforms. People who excelled with their Data Warehouses yesterday are now trying to outshine each other with Data Lakes. But if we move away from how data is managed, the focus is on the ability to create insights.
What is Machine Learning used for? Yes, the line between ML and Analytics is incredibly thin in technical terms, and you could actually say that it overlaps. However, when looking at value creation, expectations of ML normally differ from Analytics. The expectation is for ML to be able to predict the future. Now, most people know that these predictions come in the form of probabilities; there are no absolute promises here. And perhaps this makes the overlap with Analytics clearer; a lot of the things we want to predict can be related to data that gives ‘simple’ (usually linear) algorithms, which people had been working with in Analytics long before ML became popular. This is why it is normally said that 90% of all Machine Learning initiatives end in an Analytics solution. For me, the main advantage of Machine Learning is its ability to build and represent knowledge. What is important to understand is that different kinds of applications require you to represent knowledge in different ways, so the choice of algorithm and architecture is an important process, particularly when working with specific domains. Nowadays general applications often come with pre-trained models, i.e. where the knowledge is in-built.
Knowledge is only useful when it is used
So what does AI add? Well, for me it is the ability to act. We come back to the view that knowledge is only useful when it is being used. Sometimes it can involve us executing a piece of code or calling an API, while other times our AI can have cognitive abilities and can communicate via speech/images or affect the surroundings in a physical way (often referred to as a robot). And honestly speaking, there are relatively few AI solutions currently in production (apart from industrial robots).
I would like to end this on a slightly philosophical note, so I have chosen this quote:
“The goal of forecasting is not to predict the future but to tell you what you need to know to make meaningful action in the present.” – Paul Saffo
We cannot do anything about what has happened, but we can learn from what has happened.
The challenge is that the data can give us insights that are relevant under the exact conditions when the data was produced. And it is difficult to compensate for all of the changes that have taken place from the time the data was produced to the time you will act; so it is virtually impossible to understand all the possible processes that could have affected your data. This is why you want to have a colleague who thinks that statistics are fun.
Having a vision of where you are going is essential (in my opinion). But the future is an imaginary place that only exists in a person’s mind. Someone said that the surest way to predict the future is to create it.
When can you trust your knowledge?
This is because you can only have a direct influence on what is happening right now.
What is difficult to work out is when you should trust your collective knowledge and only react to things that are happening; and when you need to spend energy analysing the situation, carrying out an impact assessment and consciously acting. Afterwards you ask for feedback on your actions, so you can use experience to build new knowledge for the next time a similar situation occurs. (I realise as I am writing this that this reasoning can apply not only to me as an individual, but also to ‘an AI’.)
No human being can act rationally all of the time, as our brain consumes too much energy to do this. But try to create moments during the day when you consciously make decisions about how to act. Some people call this ‘mindfulness’; living in the present.
So a good way of managing the increasing amount of data that our brain is exposed to is to build knowledge. We do this by consuming information or by the feedback we gain from experience. With our existing knowledge, we can make decisions without having to expend as much energy. This means that we have energy left over for when it is needed.
So what are you going to learn today?
Or as people used to say:
“The best thing would have been to plant the apple tree 10 years ago; the second best thing is to plant it today.”
And of course at Softronic we can help you if your organisation wants to build knowledge, or build a process to continuously work with new knowledge.
Blog post written by Stefan Palm for Softronic AB.
